Transformer Plugin
Purpose
The purpose of this section is to explain the concept of the Transformer Plugin.
This is a plugin that comes with jazz-core. It is embedded inside same lib, so once you download the jazz-core, the Transformer plugin will come together, in same package.
The main idea of any plugin in Jazz is basically the same: get some data, do something with it and deliver a result to the user or to the next step in the pipeline. This is not different with the Transformer plugin.
Basically, it receives a raw data, and based on a list of instructions (configured in the jazz-pack file), it converts this data into a different set of data.
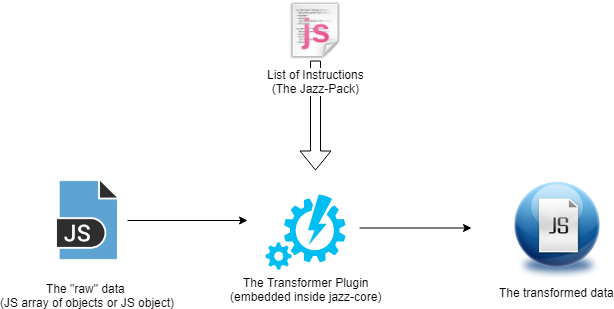
How to configure the jazz-pack to use the transformer plugin?
Let's use a real world example to explain. You have an excel spreadsheet with some data, and you need to transform this into a text file, by following some specifications on position, size, data types, mappings, ...
Your excel spreadsheet, looks like the one below (by the way, this is the example file source.xlsx you can find in the tests folder ):

This is a three step pipeline:
- extract data form excel
- transform data
- load data into text file
We will not go through details into steps 1 and 3. The only thing you need to understand is that these steps are accomplished by 2 different plugins (the jazz-plugin-excelextractor and the jazz-plugin-textloader). By the way, this is the use case implemented in this boilerplate.
OK, so moving to the step 2, which is the important one here, for the purpose of this tutorial.
- The first thing you need to do is to use the plguin Transformer, more specifically the transformer task as a step in your pipeline.
pipeline: [
`${excelExtractorPluginPath}:jazz-plugin-excelextractor:extract`,
`${excelExtractorPluginPath}:jazz-plugin-excelextractor:validate`,
/* here is the transformer plugin, task transform */
`${transformerPluginPath}:Transformer:transform`,
`${textLoaderPluginPath}:jazz-plugin-textloader:load`
];
- Second thing is to inform the source from raw data to Transformer plugin, through the plugins property, like this:
plugins: [
/* other plugins...*/
{
name: 'jazz-plugin-excelextractor',
sheet: 'source',
},
{
name: 'Transformer',
/* here you are telling the Transformer plugin that it needs to use the property in sourced object named groupid to identify a group of records - this is not required information */
groupIdColumn: 'groupid',
tasks: {
transform: {
/* here you are telling the Transformer plugin that it's source is the result of the task extract */
rawDataFrom: 'extract',
},
},
},
/* other plugins...*/
{
name: 'jazz-plugin-textloader',
tasks: {
load: {
rawDataFrom: 'transform',
},
},
},
],
- Now that your transformer plugin is in your pipeline and knows from here to get the data, it's time to tell the plugin what to do with this data.
We can achieve this by adding the groups array in the root of our jazz-pack.
The groups array
groups: [
...
]
Ok, so, now let's start adding the groups into the array. Each group is a javascript object, like this:
groups: [
{
id: 'main',
parent: ''
fieldDelimiter: '|'
sizeMode: 'fixed',
data: {
...
},
}
]
Notice here that there are 3 properties:
- id: the name of the group. It is a required information. Also, it needs to be an unique value in the pack.
- sizeMode: can be fixed or variable. Default value is fixed This determines how the information will be positioned in the group.
- fieldDelimiter: usually, when the sizeMode is variable, a delimiter char is required between values. optional.
- parent: the name of the parent group of this group. optional. It's used only in more complex use cases, in which the target data is composed by multiple groups of records
- data: javascript object containing the data configuration for the group
The data object
groups: [
{
id: 'main',
sizeMode: 'fixed',
data: {
hasHeader: false,
hasDetail: true,
detailGroup: 'pay',
hasTrailer: true,
header: {
columns: [
...
],
},
detail: {
columns: [
...
],
}
trailer: {
columns: [
...
],
},
},
},
It contains the following properties:
- hasHeader (true/false): Indicates if the group has a header record or not
- hasDetail (true/false): Indicates if the group has details records or not (usually stays between the header and trailer)
- hasTrailer (true/false): Indicates if the group has a trailer record or not
- detailGroup: The identifier of the group in the source data
- header { columns [ ... ] }: this object contains an array named columns. Consists in the columns that compose the header record
- trailer { columns [ ... ] }: this object contains an array named columns. Consists in the columns that compose the trailer record
- detail { columns [ ... ] }: this object contains an array named columns. Consists in the columns that compose the details record
The columns array
This array will contain all the columns that the target data will have. Each column is represented by a javascript object:
columns: [
{
id: 'record_type',
description: 'Record Type',
required: 'on',
type: 'text',
size: 3,
defaultValue: 'TRL',
},
{
... /*2nd column */
}
{
... /*3rd column */
}
...
]
Each column object contains a list of properties that will define how the output value will be delivered.
id: the name of the column. This will be the property name in the object which will containt the transformed data.
description: describes the meaning of the information. It's not used by the logic in an aspect. Will be usefull when we have a user interface implemented.
required (on/off): if this flag is set to on, the transformation process will raise an errorif source data is empty or do not exist
defaultValue: when informed, the transformer will not look into source data. Will just consider this default value in the output.
type: possible values are:
- text
- number
- date
size: represents the number of characters the column will have in the transformed data. This works only when sizeMode is set to fixed.
fillMode: possible values:
- zeros_on_left: will fill the value with zeros on the left side until complete the number of characters defined on _size_ property
- zeros_on_right: will fill the value with zeros on the right side until complete the number of characters defined on _size_ property
- spaces_at_end: will fill the value with spaces on the end, until complete the number of characters defined on _size_ property.
If the fillMode is not informed, the transformer will consider:
if type=text or date, fillMode = spaces_at_end
if type=number, fillMode = zeros_on_left
fillCondition: this is a function that by default, receives the row being processed in raw dat. It's required that this function return a boolean (true/false). If true, information will be feed. If false, will keep it as empty. Example:
fillCondition: ({ transaction_code }) => transaction_code == '71',In the example, the information will be empty if in the same record being processed, the value in property transaction_code is different from 71.
removeDecimalChars (true/false): if type is number and this value is set to true, will exclude the decimal chars from the number. Default is false. Example: 123,45 or 123.45 will become 12345.
numberOfDecimalDigits: Default is 0. Example ( for numberOfDecimalDigits = 2 ):
Source Output 123.45 123.45 123 123.00 123.4 123.40
- empty (true / false): if true, output will fill with blanks. Default is false. If defaultValue is set, this property will not work.
- dateFormat (wip): defines the date format for columns typed as date.
The dateFormat ix still a work in progress, so in order to achieve the right date format, this needs to be feed in the final format in the source data. Another option could be to ovewrite the preExecute method and transform the date format before move to the transform step
excludeChars: An array of characters that must be excluded from the output. The example below will remove the chars from the output.
excludeChars: ['-', '.', '/'],removeAccents (true/false): If set to true, removes the accents from the text on the output. Default value is false.
removeSpecialChars (true/false): If set to true, removes the special chacarters from the text on the output. Default value is false.
caseType (lower / upper): if lower, will transform output into lowercase. If set to upper, will set the output to uppercase. If not set will consider the data from the source as is.
transformType: This property is a very specific one. If informed, it will be required to inform the transform object. Depending on the option informed, the transform object will have different properties.
The possible values are:
- source: represents that the output will be originated from a source value in the raw data object.
- transform:
- source: the name of the property in the raw data.
- transform:
In the example below, we are telling jazz that the transaction_code field in raw data must be used to deliver the transformed data in the transaction_code field in the output object. They have the same name in here, but this is not a rule.
transformType: 'source',
transform: {
source: 'transaction_code',
}
mapping: represents that the output value will be the result of a conversion table (the conversion table will be a json file that needs to be distributed with the jazz-pack).
- transform:
- sourceOnMappingTable: the name of the column in the conversion table that holds the result value.
- caseSensitive (true/false): if set to true, the comparign between sourced data and conversion table will be case sensitive.
- mappingData: indicates the json file that will contain the conversion table.
- tableName: the name of the table in the json file. This allows the same json file to handle more than one conversion table.
- mappingKeys: an array of keys to be used to find the result information. Why this is an array? Let's say that in the sourced data you have 2 fields that will compose a single result on the conversion table. Yo could achieve this result by composing the keys like this:
[ { key: 'name', source: 'bankname' }, { key: 'name2', source: 'bankname2' } ] - useOriginalOnNotFound (true/false): if corresponding value not found and this is set to true, the source value will be considered in the output. If false (default), and the corresponding is value, an error will be raised.
- errorOnMultiple (true/false): If set to true, an error will be raised when 2 or more corresponding values are found in the conversion table. If false, output value will consider the first record found in conversion table.
- transform:
In the example below, we are telling jazz to use the banks.json file as conversion table. Also we are saying that the code field in the table is the value to be used as result.
transformType: 'mapping',
transform: {
sourceOnMappingTable: 'code',
caseSensitive: false,
mappingData: require('./mappings/banks.json'),
tableName: 'banks',
mappingKeys: [{ key: 'name', source: 'bankname' }],
useOriginalOnNotFound: true,
errorOnMultiple: true,
}
input: represents that the value will be taken from an userInputParameter.
- transform: not required
parent: represents that the output value will be the sourced to a field that is part of the parent structure. For example. Think on the follwoing structure of an output file:
parent: value1|value2|value3
child: value4|value5|(map to field value1 that is in the parent record)
- transform:
- groupId: the name of the parent group
- sectionId: the section in the parent group (field can be mapped from the header, detail or trailer)
- source: the field name in source data
transform: {
groupId: 'pay',
sectionId: 'detail',
source: 'transaction_sequence_number',
},
calculation: Works better in trailer section. Useful when you want to count or summarize the records, for example, in a trailer record of your output file.
transform:
- calculationType: possible values are...
- count: counts the number of records
- sum: summarizes the value from a specific field (field name will be indicated in property source)
- source: indicates the field name that will be used to summarize, when calculationType equal to sum.
- calcCondition: a function that receives the raw data and returns a boolean (true / false). Useful when you want your final calculation result to consider some conditions. In the example below, it will consider in the calculation only the records in which the groupid field is equal to pay:
transform: { calcCondition: ({ groupid }) => groupid === 'pay', calculationType: 'count', }The calcCondition value can be a pure pinline function, or a string referencing to a js file that will contain the function.
Then, you just need to make sure the file that contains the function will be distributed with your jazz-pack.
- calculationType: possible values are...
- sequence: useful when you have a field that will be a sequenced number, like below. The 3rd field is a sequenced number.
value1|value2|00001 value1|value2|00002 value1|value2|00003 value1|value2|00004
- transform:
- groupId: identifies the group to be considered in the sequence (see example below for more clarity)
The transform option is required only when the sequence needs to consider a group of records. Note that the sequence restarts on each new group. This can be achieve by using the sequence option combined with the options described above. In the example below, the groupId value would be equal to group1 and group2, depending on the sequence.
group1|value1|value2|00001 group1|value1|value2|00002 group1|value1|value2|00003 group2|value1|value2|00001 group2|value1|value2|00002 group2|value1|value2|00003
complex: let's say that none of the out-of-box options described fit to your transformation use case. In this case you can use the complex option. This will provide the possibility to reference to a function that will transform the data for you. This function will receive the raw data as an argument.
transform:
- func: you can set an inline function in the jazz-pack file directly. Example:
transformType: 'complex', transform: { func: (data) => { /* do something with the original data */ /* destructure to get the required field */ const { theField } = data; return newData; } },
- functionRef: a string with the function path. It's used when you don't want to polute the jazz-pack file with inline funcitons. You can this option to indicate a separatedjs file that will contain the function.

Then, you just need to make sure the file that contains the function will be distributed with your jazz-pack.